Evoluzione e scenari futuri
Web 2.0

Per le applicazioni Web 2.0, spesso vengono usate tecnologie di programmazione particolari, come AJAX (Gmail usa largamente questa tecnica) o Adobe Flex.
Un esempio potrebbe essere il social commerce, l'evoluzione dell'E-Commerce in senso interattivo, che consente una maggiore partecipazione dei clienti, attraverso blog, forum, sistemi di feedback ecc.
Gli scettici replicano che il termine Web 2.0 non ha un vero e proprio significato e dipenderebbe principalmente dal tentativo di convincere media e investitori sulle opportunità legate ad alcune piattaforme e tecnologie.
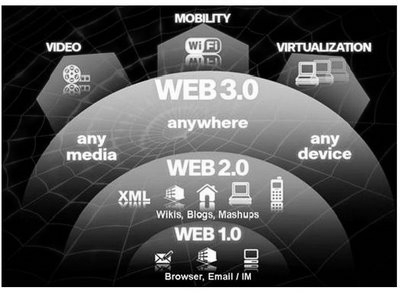
Originariamente il web è stato concepito come modo per visualizzare documenti ipertestuali statici (creati con l'uso del linguaggio HTML); questo approccio può essere definito come Web 1.0 afferente al paradigma del Web statico.
In seguito, grazie all'integrazione con database e all'utilizzo di sistemi di gestione dei contenuti (CMS), esso è stato da alcuni definito Web 1.5.
Attraverso l'utilizzo di linguaggi di scripting come Javascript, degli elementi dinamici e dei fogli di stile (CSS) per gli aspetti grafici, si possono creare delle vere e proprie "applicazioni web" che si discostano dal vecchio concetto di semplice ipertesto e che puntano a somigliare ad applicazioni tradizionali per computer.
Da un punto di vista strettamente di tecnologia di rete, il Web 2.0 è del tutto equivalente al Web 1.0, in quanto l'infrastruttura a livello di rete continua ad essere costituita da TCP/IP e HTTP e l'ipertesto è ancora il concetto base delle relazioni tra i contenuti. La differenza, più che altro, sta nell'approccio con il quale gli utenti si rivolgono al Web, che passa fondamentalmente dalla semplice consultazione (seppure supportata da efficienti strumenti di ricerca, selezione e aggregazione) alla possibilità di contribuire popolando e alimentando il Web con propri contenuti.
Web al quadrato

Tim o’Reilly, dopo aver coniato il termine Web 2.0, ha scelto Web squared per definire il prossimo stadio evolutivo del web reso possibile grazie alle tecnologie attualmente a nostra disposizione e a quelle che saranno sviluppate nel prossimo futuro.
Una rete Web al quadrato deve possedere le seguenti proprietà:
- Le informazioni in essa contenute vengono aggiornate in tempo reale;
- Gli utenti non sono esclusivamente persone ma anche oggetti;
- Ogni utente è un nodo della rete;
- L'accesso alla rete deve poter essere effettuato in piena mobilità;
Le informazioni sono descritte in maniera tale da poter essere agevolmente messe in relazione fra loro da tutti gli utenti, che siano umani o implementazioni di una certa forma di intelligenza artificiale.
La principale differenza col Web 2.0 è da individuarsi nella fonte di informazione. Nel Web 2.0 l'informazione proviene dall’utente e non dallo strumento utilizzato.
Confrontando il concetto di Web al quadrato con quello di realtà aumentata, invece, la principale differenza sta nel collegamento ad una rete. Infatti, sebbene molti degli attuali software considerati di realtà aumentata posseggano un meccanismo di connessione che ricava informazioni dalla rete, il concetto di realtà aumentata non lo prevede come condizione necessaria. È più appropriato considerare tali software applicazioni Web2.
Sotto il profilo hardware possiamo individuare, fra i dispositivi oggi presenti, gli smartphone e i palmari di ultima generazione. Questi, grazie agli strumenti di cui sono dotati (microfoni, telecamere, sensori di movimento, di prossimità e di direzione, GPS, etc.), possono fornire autonomamente e in tempo reale numerose informazioni immediatamente elaborabili.
Inoltre, vi è da considerare il sempre più crescente sviluppo dell’Internet delle cose, che vede i più disparati oggetti equipaggiati in maniera tale da raccogliere dati e condividerli in rete
Un altro esempio che mostra come la realtà aumentata e il web al quadrato vadano di pari passo è stato realizzato presso l’Arts Center di Christchurch in Nuova Zelanda.
Si tratta di una stanza buia contenente una ricostruzione virtuale di Ernest Rutherford, premio Nobel per la fisica, che racconta di come in quello scantinato abbia svolto la sua prima ricerca universitaria. Gli spettatori possono interagire ponendo domande o attraverso un’interfaccia con display applicata ad un casco.
Possibili sviluppi
L’aumento del numero di oggetti collegato all’Internet delle cose così come il costante sviluppo di software in grado di aumentare la realtà possono fornire non solo informazioni utili all’essere umano, quali luoghi vicini o commenti su un dato ristorante, ma anche dati utilizzabili dagli oggetti stessi.
Un’ipotesi di sviluppo è vista nelle Smart Grid, sistemi di gestione e ottimizzazione in tempo reale del consumo di energia elettrica.
Un’altra possibilità è individuabile nel campo pubblicitario attraverso manifesti in grado di riconoscere chi li osserva e modificarsi opportunamente fornendo informazioni sui prodotti di maggior interesse per l’osservatore.
Web 3.0

- trasformare il Web in un database, cosa che faciliterebbe l'accesso ai contenuti da parte di molteplici applicazioni che non siano dei browser; sfruttare al meglio le tecnologie basate sull'intelligenza artificiale;
- il web semantico;
- il Geospatial Web;
- il Web 3D;
- il Web Potenziato;
- la realtà aumentata.
Il termine Web 3.0 è apparso per la prima volta agli inizi del 2006 in un articolo di Jeffrey Zeldman critico verso il Web 2.0 e le sue tecnologie associate come AJAX.
Le tecnologie Web 3.0, come ad esempio un software intelligente che utilizza dati semantici, sono state implementate ed usate su piccola scala da molteplici aziende con l'intento di manipolare i dati più efficientemente.
Negli anni recenti, tuttavia, ci si è concentrati anche nel fornire tecnologie Web semantiche al pubblico generico.
Alcune start-up come Garlik, Metaweb, Radar Networks e Powerset sono fra quelle che nel 2006-2007 hanno ricevuto un'ampia copertura mediatica relativamente al campo dell'innovazione.
Un percorso evolutivo verso l'intelligenza artificiale
Il Web 3.0 è stato anche utilizzato per descrivere un percorso evolutivo per il Web che conduce all'Intelligenza Artificiale capace di interagire con il Web in modo quasi umano. Alcuni scettici credono invece che ciò sia impossibile da raggiungere. Nonostante ciò, aziende come IBM e Google stanno implementando nuove tecnologie che stanno ottenendo informazioni sorprendenti come prevedere le canzoni più scaricate, attraverso il data mining, sui siti Web universitari.
L'archiviazione e lo studio delle informazioni che riguardano l'interesse espresso durante la navigazione da parte di un software evoluto oppure la possibilità di trasferire sensazioni, esigenze, gusti e comportamenti, nel campo
In linea con l'Intelligenza Artificiale, il Web 3.0 potrebbe costituire la realizzazione e l'estensione del concetto di Web semantico. I ricercatori accademici stanno lavorando per sviluppare un software per il ragionamento, basato sulla logica descrittiva e sugli agenti intelligenti. Tali applicazioni possono compiere operazioni di ragionamento logico utilizzando una serie di regole che esprimano una relazione logica tra i concetti ed i dati sul Web.
Fonte: Wikipedia
Commenti
Posta un commento