
Nelle reti a pacchetto, i pacchetti attraversano una grande quantità di dispositivi diversi, come ad esempio router, switch, bridge. Questi dispositivi, e i collegamenti che li interconnettono, hanno capacità di elaborazione e di trasmissione limitate che possono portar, a situazioni di congestione, cioè a situazioni nelle quali i nodi non sono in grado di smistare tutto il traffico offerto in ingresso da varie connessioni tra utenze causando perdita di pacchetti e/o eccessivi ritardi.
Il controllo della congestione permette di migliorare le prestazioni della rete evitando perdite di pacchetti e limitando il ritardo a causa delle ritrasmissioni dei pacchetti persi.
Da non confondere con il controllo di flusso che è un meccanismo di controllo di trasmissione che è dato dalle capacità esclusive del destinatario ed è finalizzato a non eccedere la capacità di elaborazione e memorizzazione del solo ricevitore da parte del mittente.
Esistono, quindi, almeno due problemi importanti, nel TCP, relativi alla congestione della rete ed al meccanismo di timeout and retransmission.
La congestione può essere definita come una condizione di ritardo critico causata da un sovraccarico dei datagrammi in uno o più switching points (ad esempio il router). Quando avviene un evento di congestione, il ritardo aumenta ed i router iniziano ad accodare datagrammi, finchè non sono più in grado di instradarli.
Nel caso peggiore il numero dei datagrammi che arrivano ad un router congestionato cresce, in modo esponenziale nel tempo, fino a che esso non raggiunge la sua capacità massima e comincia a perdere datagrammi. Dal punto di vista degli host, la congestione è semplicemente un aumento di ritardo.
Poichè la maggior parte dei protocolli utilizza un meccanismo di timeout and retransmission, essi rispondono al ritardo ritrasmettendo datagrammi, aggravando ulteriormente il fenomeno di congestione.
Un aumento di traffico produce un aumento di ritardo, che a sua volta provoca un aumento del traffico, e via di seguito, fino al punto che la rete non può essere più utilizzat. Tale condizione è detta Congestion Collapse (Collasso dovuto alla congestione).
Riepilogo
La congestione,tecnicamente, può essere dovuta a:
- un numero elevato di sorgenti di traffico
- sorgenti di traffico che inviano troppi dati
- traffico inviato ad una frequenza troppo elevata
- In presenza di questi fenomeni, singoli o concomitanti, la rete è sovraccarica
Gli effetti sono:
- perdita di pacchetti:
- buffer overflow nei router
- ritardi nell’inoltro dei pacchetti:
- accodamenti nei buffer dei router
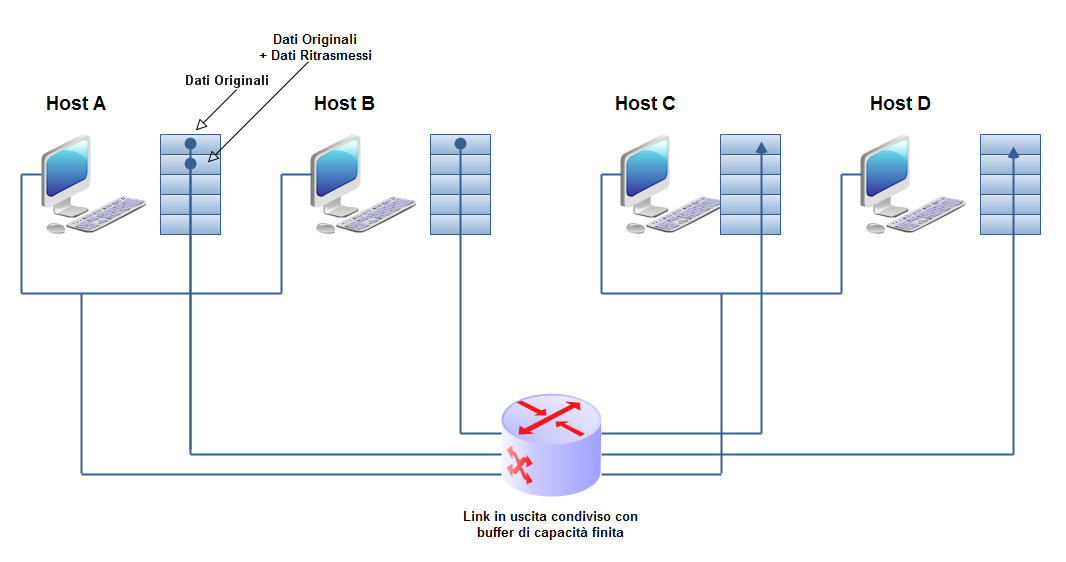
Un esempio
- 2 mittenti
- 2 riceventi
- 1 router con buffer (coda) ∞ :

L'esito sarà:
- non ci sono ritrasmissioni
- I ritardi aumentano all'avvicinarsi del limite di capacità del canale
- Non si può superare il max throughput

Non esiste un meccanismo esplicito ed univoco per risolvere il controllo della congestione, anche se un'attenta implementazione del TCP/IP permette di individuare ed affrontare la situazione.
Esistono due modi per affrontare il problema della congestione di rete:
- recuperare la funzionalità una volta che la congestione ha avuto luogo (Recovery);
- evitarla (Avoidance).
Per evitare il collasso della rete, il TCP può utilizzare la tecnica definita del Multiplicative Decrease Congestion Avoidance. Il TCP/IP, in questo caso, mantiene un secondo limite, oltre la dimensione della finestra del ricevente, detto congestion window limit: ad ogni istante il TCP assume come dimensione della finestra di trasmissione, la minima tra le due.
In condizioni normali, le due finestre sono uguali, ma in quelle di congestione, la congestion window riduce il traffico che il TCP immette in rete, dimezzando, così, la propria dimensione ogni volta che si perde un segmento (fino ad un minimo di uno). Il rate di trasmissione è ridotto in modo esponenziale ed il valore del timeout viene raddoppiato per ogni perdita.
Se, una volta superata la congestione, si dovesse invertire la tecnica del Multiplicative Decrase, raddoppiando la congestion window, si avrebbe un sistema instabile che, quindi, oscillerebbe ampiamente tra:
- assenza di traffico;
- congestione.
Per ripristinare le condizioni normali, una volta che è avvenuto il collasso, il TCP può adottare una tecnica di Slow Start Recovery. Non appena inizia il traffico su una nuova connessione o aumenta dopo un periodo di congestione, la congestion window assume la dimensione di un singolo segmento ed ogni volta che arriva un ACK, viene incrementata di uno.
Così, dopo aver trasmesso il primo segmento ed aver ricevuto il suo ACK, la finestra di congestione viene raddoppiata: una volta inviati i due segmenti, per ogni ACK ricevuto la congestion window sarà incrementata di una unità, così il TCP potrà spedire quattro segmenti, e così via, fino a raggiungere il limite imposto dalla finestra del ricevente.
Per evitare che la dimensione della finestra si incrementi troppo velocemente e causi, quindi, congestione addizionale, il TCP impone una ulteriore restrizione. Una volta che la finestra di congestione raggiunge la metà del suo valore originale, il TPC entra in una fase di congestion avoidance e rallenta, così, il rate di incremento. In questo caso la dimensione della finestra sarà incrementata di una sola unità dopo che tutti i segmenti della finestra hanno ricevuto l'ACK.
La combinazione delle due tecniche di Recovery ed Avoidance migliora enormemente le prestazioni del TCP senza bisogno dell'aggiunta di ulteriori strumenti per il controllo della congestione.
Fine della parte 9
Commenti
Posta un commento